How to remove Mi Account Lock from Xiaomi - step-by-step instructions
How to remove Mi Account Lock from Xiaomi - step-by-step instructions
In this article, we will talk in detail about how to remove Mi Account from Xiaomi devices and consider what is needed for this. We will also get acquainted with the terms, current prices and answer popular questions:
- are there any risks?
- is it temporary or permanent?
- can I delete it myself?
- are there any restrictions?
And now about everything in order.
What is Xiaomi Mi Account?
Xiaomi, following the example of Apple with their iCoud services, has developed its own cloud storage - Mi Cloud, which "binds" the device to the user account. Xiaomi Account allows you to synchronize the work of different devices of this brand with each other and, as in the case of Apple, enable remote "search" of the device in case of its loss.
Is it possible to delete Xiaomi Account and will there be any risks?
Unlike the iPhone, removing the lock from the Xiaomi device is much easier. The device is completely and permanently "unlinked" from the account of the previous owner, without the risk of re-blocking. After deleting the account, the device can be configured for any other data and create a new account on it. The former owner will not be able to detect the untethered device, the data about it will be deleted. Thus, removing the Mi Cloud lock will have no consequences.
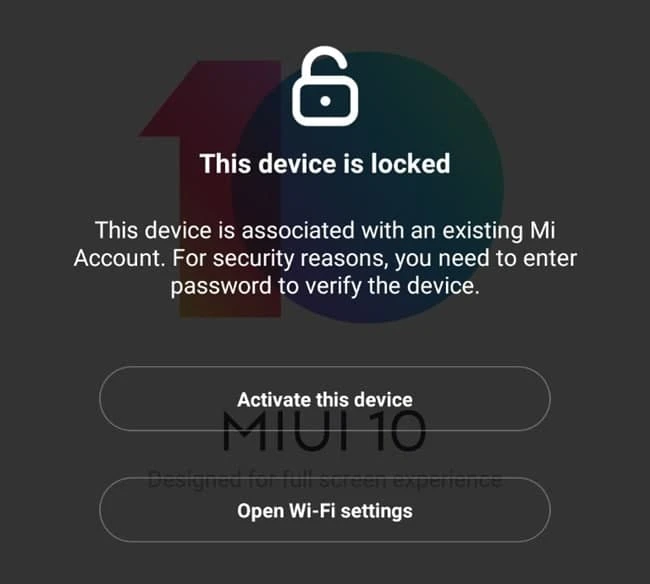
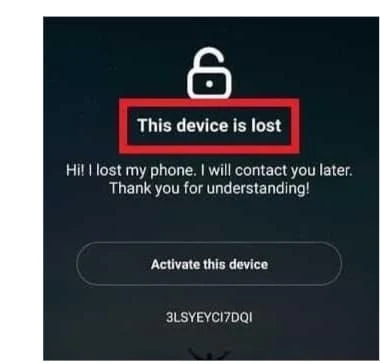
It is important to note that you can remove the lock only from a "clean" Xiaomi, that is, one that has not been declared lost or stolen. "Clean" Xiaomi devices are designated by the word CLEAN, and lost ones are designated by the word LOST. If you try to unlock a lost device, nothing will happen - your request will simply be rejected as unsuccessful. But if you know for sure that the phone is lost, trying to unlock it under the guise of "clean" does not make sense, since at the moment unlocking such devices is not available worldwide.
How to check Xiaomi for CLEAN/LOST status (stolen or not)?
The easiest way to accurately check Xiaomi for the lock status - missing or not, is to use a paid check on the service imei-server.ru - Xiaomi - Checking Mi Account Lock: [CLEAN/LOST]. This check works both by device NAME, serial number and Lockcode. This way you will be able to accurately determine whether your device is subject to untying.
In most cases, a "clean" device will display an inscription on the screen - "This device is locked", while a lost one will immediately show - "This device is lost".
Which Xiaomi models are supported for unlocking from Mi Account?
The answer is simple - any, since the model does not matter when deleting an account. The architecture of all Xiaomi models in terms of security and principles of working with Mi Cloud has no significant differences. The only thing that can affect the success of the deletion is the country in which the account was created. The good news is that the success rate of removing the lock from any "clean" Xiaomi devices is 99.9% if the country of the account owner is NOT China.
Unfortunately, there are still no services for devices from China, even in the CLEAN status. All other countries are supported. The full list of services is available here - Mi Account Lock removal services from Xiaomi devices of different countries
Is it possible to remove Xiaomi's Mi Account lock yourself?
If by "independently" we mean the possibility of "untying" the device for free and without leaving home, then alas, there are no such options. The choice is only that - contact a specialized service (to the master), or place an order online. Whoever unblocks, the result will be the same - the account will be deleted forever, finally and irrevocably. The difference can only be in price and timing.
Current prices and terms for removing the Mi Account Lock (24.01.2022)
*Attention: The prices and terms given below may be changed by providers at any time without notice. We recommend checking the relevance of the offer in the chat or support support@imei-server.ru before placing an order.
For advice on removing the Mi Account Lock, also contact the online help chat or email support@imei-server.ru


