Oculus Link: how to increase the resolution on the Oculus Quest

Now you can manually increase the image resolution using Oculus Link that can provide a clearer picture on the Oculus Quest.
Note: this feature is for advanced users. However, there should be no risk to your Quest, or performance, because you can just set any changes to default if something goes wrong.
Oculus Link is a new feature for offline Facebook Oculus headset Quest, which allows it to act as a VR headset to PC using any high quality USB 3.0 cable. Currently it is in beta.
The output resolution of the Oculus Link default is lower than when using the Rift's that makes an image less sharp and smoother. But Facebook, who created the latest public test channel Rift software (the channel name beta Facebook), allows advanced users to change the resolution, and the graphical encoder Volgaksoy Facebook has published a guide on how to do it.
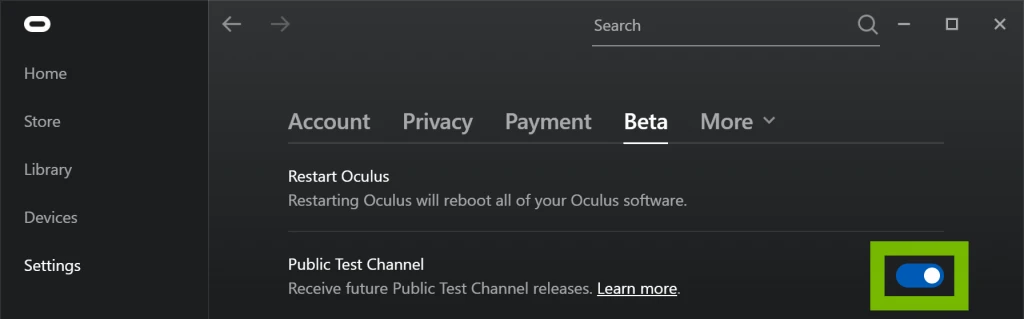
To make sure you are connected to a public test channel Rift, go to settings app and click the tab "Beta".
Oculus Debug Tool
To change the resolution of the Oculus Link, Oculus you use Debug Tool (ODT). It can be found in the subfolder Oculus-Diagnostics the Support folder of your directory software Oculus Rift. By default this will be C:Program FilesOculusSupportoculus-diagnostics.
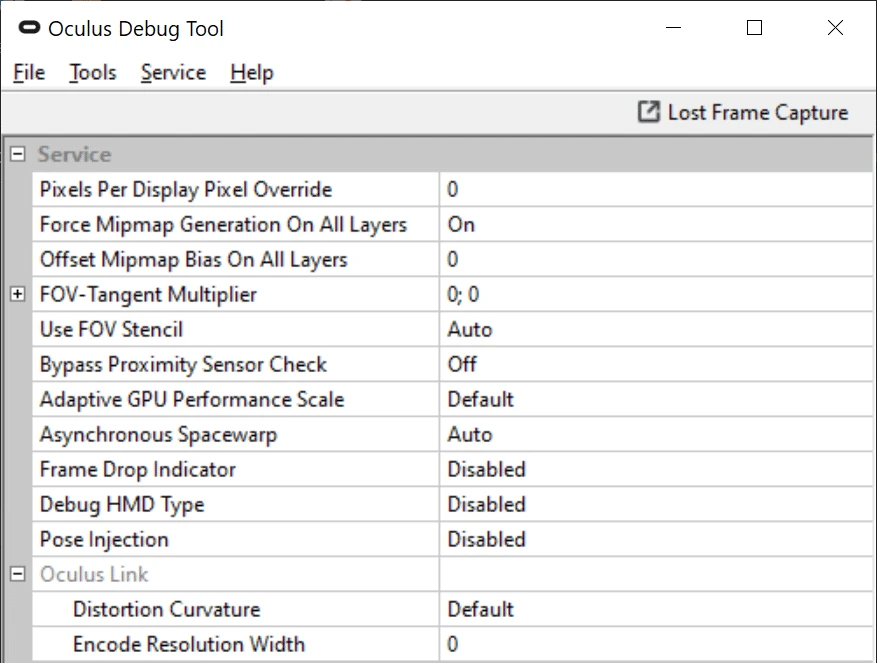
The program is called OculusDebugTool.exe .
Pixel density, resolution, encoding, curvature
Three settings in the ODT that relate to the Oculus Link:
Pixels Per Display Pixel Override is a decimal number that sets the actual resolution of the rendering of the VR application. 1.0 is the default value. This value for each axis, so the value 1.2 actually means that 44% more pixels displayed than the default.
Distortion Curvature: although this parameter is not given in the description, it likely specifies a curve in which resolution is reduced in the periphery. Contrary to common sense, "low" gives better quality than "high".
Encode Resolution Width: Oculus Link works by sending a compressed video stream via a USB connection. This parameter determines the resolution of the video stream.
Pixels on the display will always return to 1.0 when the computer is restarted, however, the Distortion Curve and Encode the Width will remain.
Width of rendering in Pixels Per Display default (1.0) is equal to 1800. Encode the Width of the default, apparently, 2016. However, you can also return them to the default value by setting the value to 0.
Encode the increase in Width without increasing the multiplier Pixels Per Display, as a rule, pointless.
Recommendation Oculus
Three recommendations-level of quality based on what generation of graphics card you have:
NVIDIA GTX 970+ or Comparable
- Pixels Per Display Pixel Override - 1.0
- Distortion Curvature: Default
- Encode Resolution Width: 2016
NVIDIA GTX 1070+ or Comparable
- Pixels Per Display Pixel Override - 1.1
- Distortion Curvature: High
- Encode Resolution Width: 2352
NVIDIA RTX 2070+ or Comparable
- Pixels Per Display Pixel Override - 1.2
- Distortion Curvature: Low
- Encode Resolution Width: 2912
Warning Oculus
Warning for too high settings:
- Higher "pixel density" can lead to the disappearance of the personnel of the VR application and will depend on the performance of the VR application.
- The more "high resolution encoder"can lead to a drop in personnel of the composer, as well as to visible gaps.
- Higher resolution in General can also lead to increased latency.
- Overly high resolution (especially the "Resolution encoding") can lead to aliasing artifacts (i.e. bypass pixel), high-frequency details.


